
AI-Assisted eLearning Review System.
My Role
Cross-functional contributor on a team building an AI-powered SCORM course quality review system. I worked across UX design, AI training data creation, LLM model evaluation, UI/UX QA, and product roadmap recommendations, spanning almost every stage of the product development lifecycle in a single project.
The Problem
Course creators building eLearning content face a consistent quality challenge: manually reviewing courses for grammar issues, terminology inconsistencies, unclear instructions, and structural problems is time-consuming and error-prone. The system I contributed to was designed to automate this review using a combination of rule-based checks and LLM analysis, generating structured reports that identify issues, their locations, and suggested fixes.
Skills Demonstrated
AI/LLM evaluation · Precision & recall metrics · Data annotation · Figma · UX design · UI/UX quality assurance · Product road mapping · Technical documentation · SCORM/eLearning domain knowledge · Systems thinking
What I Contributed.
Phase 2 Product Recommendations After reading the technical architecture documentation, I proposed feature improvements for the next development phase, documenting each recommendation's rationale, expected user benefit, and implementation approach. This was my most PM-forward contribution: synthesizing technical constraints with user needs to inform what to build next.
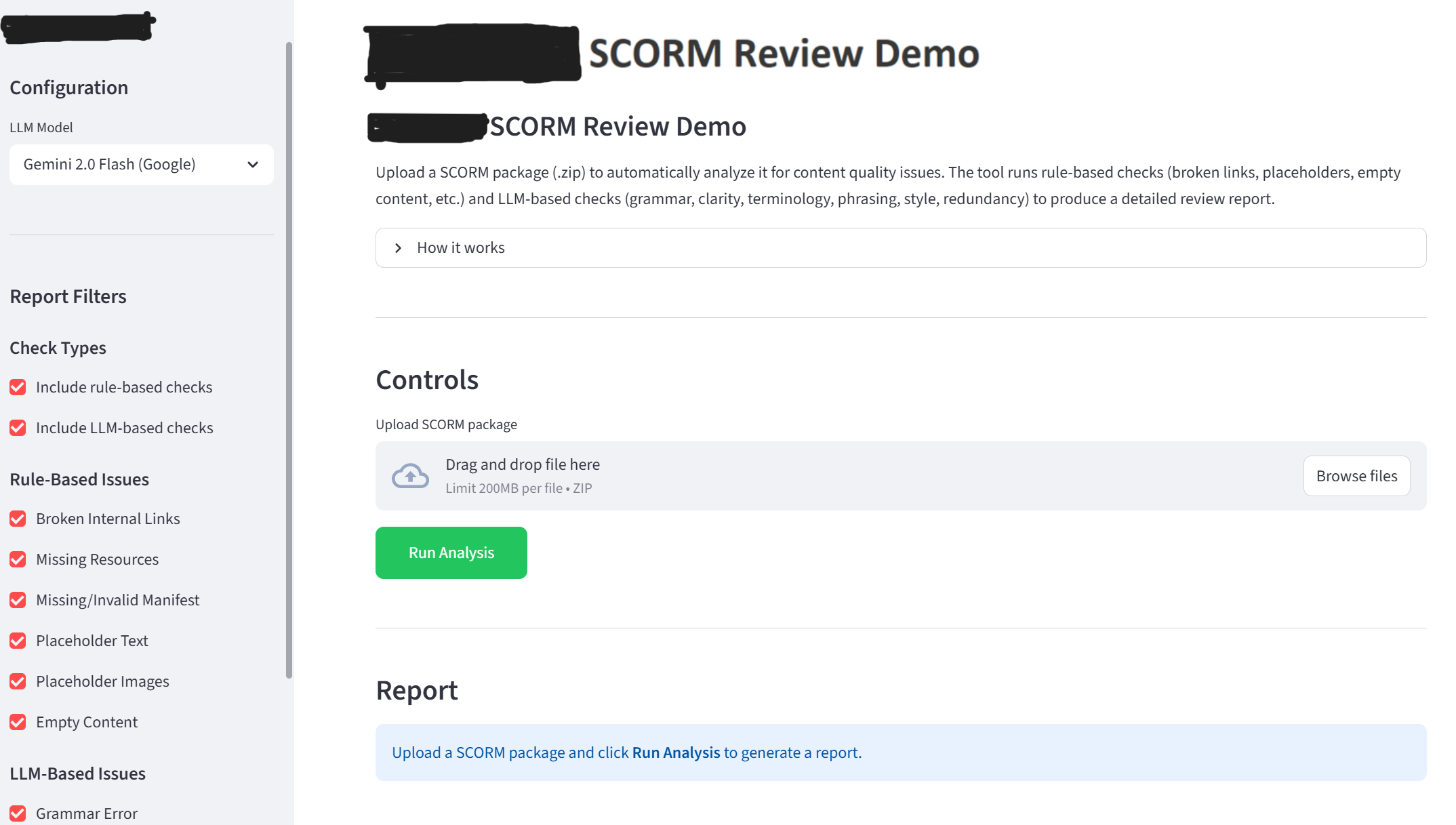
UI/UX Quality Assurance I systematically tested the deployed Streamlit application across five criteria: visual design, layout and structure, clarity and copy, user experience, and accessibility. For each issue I identified, I documented the problem, suggested fix, and a screenshot. This QA pass identified friction points before the system reached real course creators.
LLM Evaluation — Claude vs. Gemini I evaluated AI model performance on a SCORM package dataset, reviewing unmatched flags and classifying each as a false positive (not actually an issue) or an extra viable flag (a valid issue not in the ground truth). From this, the precision and hallucination metrics for both Claude and Gemini were calculated, generating data that directly informed which model to use in production.

Ground Truth Annotation I reviewed a live SCORM course package section-by-section, documenting quality issues including grammar errors, unclear instructions, terminology inconsistencies, awkward phrasing, and redundant content. Each issue was logged with its type, severity, exact location, original text, and suggested fix. This annotation dataset became the ground truth used to evaluate the AI model performance.
AI Training Data — Pattern Library I created approximately 20 annotated examples for the terminology inconsistency issue type, showing the LLM what the problem looks like and what it doesn't. Examples covered patterns like inconsistent hyphenation, mixing formal and informal terms for the same concept, and inconsistent capitalization. These examples directly shaped what the LLM learned to detect.
UX Design & Interface Development I co-designed a Figma mock-up for the Streamlit demo interface: the front end that course creators would use to upload packages, configure analysis settings, and review flagged issues. The mock-up established the full user flow and information architecture before any code was written, reducing the risk of expensive UX rework later. I then led a developer huddle to guide implementation of the skeleton application code.
Key Insight.
Good AI systems require high-quality human judgment at every layer: the training data, the evaluation methodology, the UX that makes outputs usable, and the product decisions that determine what gets built. This project gave me end-to-end exposure to the human-in-the-loop process in all of those layers in a single engagement.
What I'd Do Differently
I worked mostly independently on my assigned tasks. In hindsight, I'd have initiated more peer discussion on borderline annotation and evaluation cases. Comparing judgment calls with other cohort members would have improved consistency and deepened learning. I'd also have asked more "why" questions about the architectural decisions earlier, rather than focusing primarily on task execution.